
Series index

Beginning Well
The old saying from Franklin Covey is:
Begin with the end in mind
Indeed, it is odd to close the series with a blog about deployment and release when they are so fundamental to success. Folks from the XP and code craft world see no reason to write a line of production code if they have not already established version control, a test pipeline, and automatic deployment.
Setting up a conventional application and pipeline is trivial and a bit tedious, so lately we find an LLM can do it quite handily for us. We also find it useful to create a few helper scripts.
Why start with deployment?
As we work iteratively and in “walking skeleton” style, we let our sponsors and/or customers see our progress and assess our work in the “daily” builds.
The running, tested code displays progress, inspires feedback, and does no damage to the company or customers.
There is an advantage in that our work is accessible and visible, which reduces the urge of other people to micromanage us.
We can also do gap analysis between the new system we are developing and whatever processes we may be automating or replacing. Whether it leads to a shorter development contract or a longer one, it should result in developing the program that serves the customers’ needs best.
Why not wait a fortnight to deploy?
This is a common question.
The answer is we CAN, of course. We can do nearly anything.
It’s more work if we wait
If the change we’re testing and releasing is only five or six lines of code in two or three files, then it’s inexpensive and effortless to release. If we have sufficient tests, then we are reasonably sure the changes are correct and complete (enough).
If we stockpile many hundreds (or, God forfend, thousands) of lines of change before we try to make a release, then it’s a different story. There are too many things that can go wrong. There can be hidden bugs, big changes in security, big changes in performance, or perhaps we have divergent changes where one set of changes makes another set invalid.
The work of making a big release is a huge effort. Most people who release only once every year saw that they would need as many as 6 months of hardening and testing to release. When they went to once a quarter, it took several weeks. When they went to once every two weeks, it took only days.
Small releases require small efforts.
It withholds value
Are you holding value hostage? If you are doing the most important work first, then the work that has been finished is pent-up value.
If you don’t release it, but rather wait for lower-value work to be done, then you are effectively holding high-value, completed work hostage for low-value work completion.
Does it make sense to withhold value from the project sponsors and users?
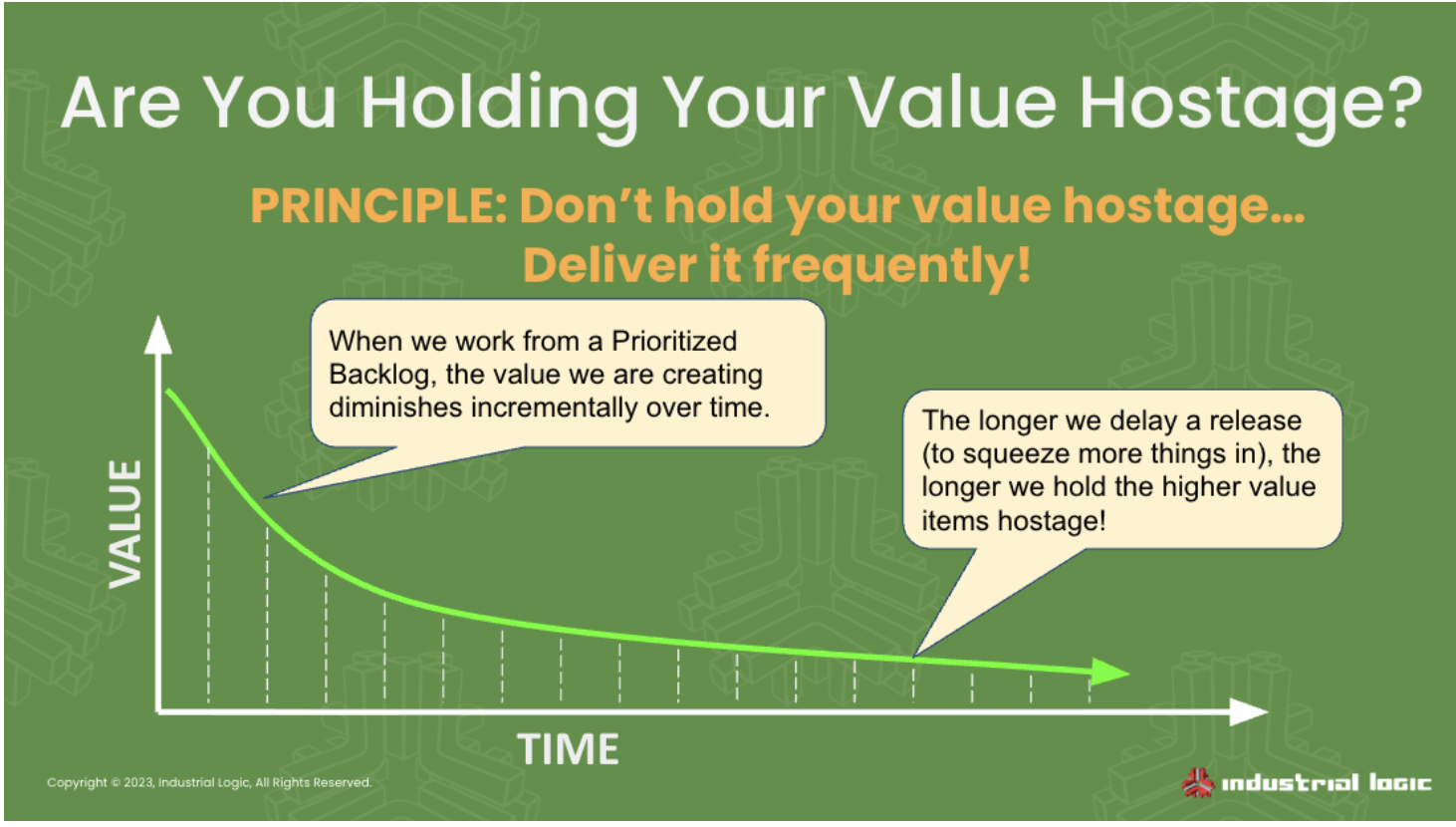
This is why we tend to ask what would happen if we released it today?
We would like for that to be met with a business decision instead of not fear and panic.
If it is always ready, it’s not scary.
Waiting Defers Feedback
Let’s reiterate the process value of early feedback.
- If all of our progress is visible at least daily, our sponsors and managers can see that we are working and plan for our actual rate of progress.
- Silence inspires micromanagement, whereas honest visibility inspires trust. Which do you find more pleasant and useful?
- If they can touch it and try it, they are likely to spot UI and UX issues our scripts cannot.
- Every deployment attempt tests the delivery system and all the Infrastructure As Code (IaC) work we’ve done.
So why would we want to wait?
But why start with a test runner?
We fully intend to deliver many times a week, possibly many times a day.
If we are delivering to a visible and accessible place (sandbox or production) where customers will interact with our work, then we don’t want to ship any disasters to them.
We use extensive automated testing to show that we’ve not broken any functionality (yet).
We won’t have time for extensive manual testing.
If this is true on the staging build, it’s doubly true of production.
What do we test?
- If code makes any decisions or transformations, we should have tests.
- Changes to business behaviors and flows may require tests.
- Every important E2E function needs automated checks.
- Important exceptions need automated checks.
- Content changes typically don’t require automated tests.
- Cosmetic changes don’t generally need automated tests.
- Pure plumbing code probably doesn’t need unit tests, as problems there will show up in a higher level of testing.
How do we test?
- Microtests are unit tests that help us write and refactor code.
- Unit Tests may be larger in scope than microtests, checking larger behaviors in code.
- Component Test are those for entire subsystems or microservices.
- End To End (e2e) tests ensure that the UI allows a user to perform a function.
- Human Beings can tell if the system is easy enough to understand, to use, and to fit into the daily flow. They can tell if it’s too lax about inputs or does not respect configuration options. They spot cosmetic issues, too.
One of the things we cannot tolerate is flaky tests. We never want to deploy broken code. If tests are intermittent, then we may have code that doesn’t always work. Maybe the test is poorly written, and the code is fine, but should we take that chance? Why aren’t the tests proof of function?
Likewise, slow tests will delay our deployments. We want all our code to be deployed without error ASAP. To ensure this, we like to run all our tests while we’re working on our development computers before pushing it to CI.
I don’t see any of these as dispensable. They all seem deeply important if we are to make a new release in minutes-to-hours from now.
Don’t Ship Half-Done Work!
We work in E2E slices, so the system is working early and often. Early slices are limited, but functionality grows more competent and complete over time. All the parts that have been written work as an integrated (if thin) whole.
Thin slicing like this is helpful if you wish to allow your sponsors to say that’s enough of this feature, let’s move on to something more important.
Top secret pro tips:
- Sometimes our sponsors and BAs will realize after we’ve done the most important 50% of a feature that the remainder isn’t all that important
- It can be helpful to our managers if they can cut scope in order to make their promise dates. If we deliver all the work they specified in one fell swoop, we rob them of the opportunity.
- Remember what I repeatedly said about micromanaging?
- You are more safely interruptable if you’re not trying to keep a huge changeset in your head.
You may find that the visual verification of progress and quality is far more valuable than the convenient familiarity of working on huge changes before eventually merging and deploying.
Is This Asking Too Much?
Many companies deliver software to production many times per day. Even our small website group can deliver a dozen times a day to production. This isn’t unheard-of or strange, it’s the practice known as Continuous Deployment.
Every team has constraints and context that may make some of these practices challenging. We understand that. It doesn’t make the work impossible.
I am a huge fan of working in a Trunk-Based way and delivering to production many times a day, but I have worked in regulated environments and mixed hardware/software where this kind of change isn’t as straightforward. In one project, we worked on delivering to a hardware-in-loop test environment at least until they were able to make a virtual hardware environment and deliver to it.
Do We Have To Work This Way?
No. I can’t tell you what you have to do. I’m not the boss of you.
OTOH, you may be having trouble making releases safely. The old saying is:
If you keep planting the same seeds, you will keep harvesting the same crop.
You may be in a team where the DORA metrics are being tracked. If so, then the person who really is your boss is telling you to work in a similar way so you improve the measured capabilities.
If you follow all the articles in this series, it should help you avoid or minimize many of the problems organizations face in moving to continuous delivery.
If you aren’t using the DORA metrics, you are still doing the right thing if:
- You can develop the deployment process with tight feedback loops
- Deployment becomes a frequent non-event
- You are able to give real, verifiable proof of progress as it happens
- You experience high pass rates through the quality gates
I wish you well.



